
Word Embeddings 2
An Intuitive Understanding of Word Embeddings: From Count Vectors to Word2Vec - 번역 (2)
개인 공부 용 번역글 입니다.
Reference:
An Intuitive Understanding of Word Embeddings: From Count Vectors to Word2Vec
Prediction based Vector
Word Embeddings (1) 에서 단어를 vector화 하는 것에 관한 deterministic한 방법들을 살펴보았는데, 이 방법들은 word2vec에 비해 단어의 특성을 표현하는데 있어서 제한적이었다.
Mitolov가 제안한 word2vec의 경우 prediction 기반의 embedding 방법으로, 단어 유추 및 단어 간 유사성에 관련된 작업들에 대해서 최고의 성능을 보이고 있다. (예를 들어 word2vec을 이용해서 King - man + woman = Queen 과 같은 결과물도 얻을 수 있었다.)
Word2vec은 문맥(Context)으로부터 한 단어를 추측해내는 CBOW(Continuous bag of words) 와 한 단어로 부터 문맥을 Skip-gram 모델 조합으로 이루어져 있다. (Context란 한 단어 또는 여러 개의 단어 그룹을 의미한다.) 두 모델 모두 neural network 를 이용하여 데이터를 학습시킨다.
CBOW (Continuous bag of words)
CBOW 모델은 주어진 문맥(context)에서 어떤 단어의 확률을 예측하는 모델이다.
예를 들어 다음과 같은 코퍼스가 주어졌다고 가정하자.
C = “Hey, this is sample corpus using only one context word.”
Context window = 1일 때, 다음과 같이 CBOW모델의 학습데이터를 구성할 수 있다.
- Input, Output 1 = (Hey, this)
- Input, Output 2 = (this, Hey)
- Input, Output 3 = (this, is)
- Input, Output 4 = (is, this)
…
- Input, Output 16 = (context, word)
- Input, Output 17 = (word, context)
이때 각 Input, Output 은 one-hot 인코딩된 단어 vector로 표현된다.
Input, Ouput1의 예시:
- Hey = [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- this = [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
CBOW 모델의 도식적 표현은 다음과 같다.
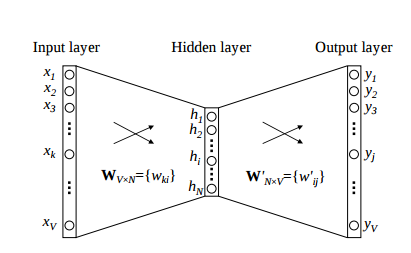 (Reference: https://www.analyticsvidhya.com/blog/2017/06/word-embeddings-count-word2veec)
(Reference: https://www.analyticsvidhya.com/blog/2017/06/word-embeddings-count-word2veec)
- Input Layer: [1 X V] (one-hot encoding)
- Hidden Layer: [V X N] (N: hidden layer의 뉴런 개수)
- Oputput Layer: [1 X V] (one-hot encoding)
위 예시는 context winow = 1인 경우로, 여러 단어를 가지는 문맥일 경우는 다음과 같이 표현할 수 있다.
예: context window = 3인 경우

(Reference: https://www.analyticsvidhya.com/blog/2017/06/word-embeddings-count-word2veec/)
Skip-Gram Model
Skip-gram 모델은 CBOW 모델과 정반대로, 하나의 단어에서 context(하나 이상의 단어 그룹)를 예측하는 모델이다.
참고: CBOW와 Skip-gram모델의 차이를 직관적으로 잘 표현해주는 그림

(Reference: https://textprocessing.org/wp-content/uploads/2017/03/CBOW-SKIPNGRAM.png)
앞선 CBOW 의 예제 corpus에서, context-window = 1일 때, 다음과 같이 Skip-gram model의 학습 데이터셋을 구성해 볼 수 있다.
- Input, Output 1 = (Hey, [this, <padding>])
- Input, Output 2 = (this, [Hey, is])
- Input, Output 3 = (is, [this, sample])
…
- Input, Output 10 = (context, <padding>)
Skip-gram 모델의 도식적 표현은 다음과 같다.
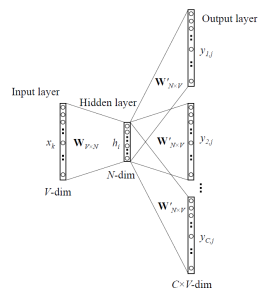
(Reference: https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2017/06/05000515/Capture2-276x300.png)
번외
word2vec에 관한 요약글을 번역하고 관련 자료들을 찾아보다가 개인적으로 느낀점은 겉핥기 식으로 핵심 아이디어는 알 수 있었지만, 짧은 설명으로 명확하게 이해되지 않는 부분이 많아서 원 논문을 보거나 자세히 설명된 강의 자료를 보는 것이 더 낫겠다는 생각이 들었다. 그냥 찬찬히 공부해봐야지. (; ㅁ ;)
-
Stanford cs224n NLP 강의: http://web.stanford.edu/class/cs224n/syllabus.html
-
Word2vec paper: Efficient Estimation of Word Representations in Vector Space